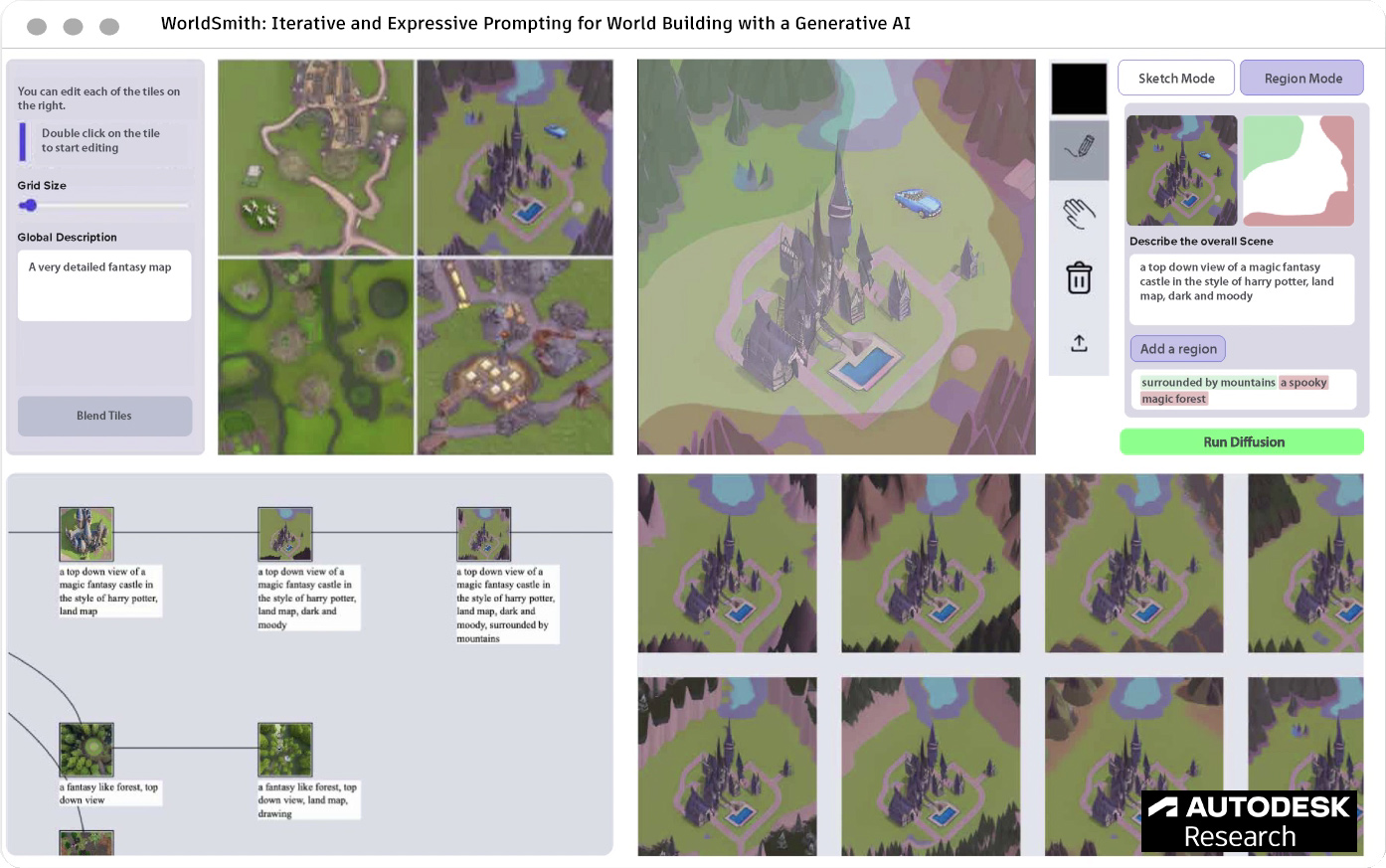
tl;dr: Creators can use WorldSmith, a multi-modal generative AI tool, to quickly design and refine fictional worlds via text, sketches, and region-based edits.
Crafting a rich and unique environment is crucial for fictional world-building, but can be difficult to achieve since illustrating a world from scratch requires time and significant skill. We investigate the use of recent multi-modal image generation systems to enable users iteratively visualize and modify elements of their fictional world using a combination of text input, sketching, and region-based filling. WorldSmith enables novice world builders to quickly visualize a fictional world with layered edits and hierarchical compositions. Through a formative study (4 participants) and first-use study (13 participants) we demonstrate that WorldSmith offers more expressive interactions with prompt-based models. With this work, we explore how creatives can be empowered to leverage prompt-based generative AI as a tool in their creative process, beyond current "click-once" prompting UI paradigms.